移动语义与智能指针
接下来这一部分内容,是现代 C++ 中非常重要的一环,但也是非常难以理解的部分。我会尽量把它讲明白,但也有可能讲不明白。
C++11 引入了移动语义(Move semantic)。这里的“移动”是相对于“复制”的意思。在第五、六章中我很详细地讲解了复制构造函数和复制赋值运算符重载;这两个函数的作用都是将一个对象复制成两个,类似于文本编辑里的“复制”-“粘贴”。而这里的移动语义则是“剪切”-“粘贴”:当调用“移动构造函数”或者“移动赋值运算符重载”时,原有的对象被“剪切”,“粘贴”到新的对象。
刚刚我尽量形象地描述了移动语义的含义,但实现移动语义则需要很多前置知识,所以我要在后面几节一点点展开。首先要重申的第一个概念是值类别。
值类别:泛左值与纯右值
任何表达式都有一个值类别;换而言之,一个表达式要么是左值,要么是右值。之前我是这样介绍的,可以取地址的表达式为左值,反之为右值;这样说是有失偏颇的,因为标准文本是反过来定义的:左值可以取地址,右值不可以取地址。换而言之,可否取地址不是左右值的定义,而是它的性质。那么左右值的定义到底是什么呢?
这个问题目前我无法给出答案,但我可以给出答案的是两个不同的概念:泛左值(glvalue)和纯右值(prvalue)。泛左值是指,具有身份(Has identity)的表达式。反之,纯右值是没有身份(No identity)的表达式。
这个定义是 C++ 之父 Stroustrup 提出的,是我认为最好理解的一种描述方式——但还是略抽象。什么叫“身份”?我把它翻译为“可识别为独一无二实体”的性质。比如中国居民,每个居民都持有独一无二的身份证,我可以通过身份证确定两个称呼是否指代同一个人,因此中国居民是有身份的。回到编程的话题上,下面的代码中
的这两个表达式都是有身份的,也就是泛左值表达式。因为,x 这个表达式和 y 这个表达式指代的并不是同一实体:一个指代变量 x,另一个指代变量 y。尽管它们类型相同,甚至在运行时具有相同的值,但由于身份不同,我不可能认为对 x 表达式操作和对 y 表达式操作是等价行为。反之,下面这段代码
int main() {
42; // 表达式 1
40 + 2; // 表达式 2
}
这里的两个表达式都不具有身份,因此它们都是纯右值表达式。为什么说它们没有身份?因为 42 和 40 + 2 的值相同,它们用来初始化变量,或者作为操作数的效果都是相同的。总结下来,两个值相同的纯右值表达式无法区分彼此,但两个值相同的泛左值表达式可以明确地通过其所指代的实体来区分。
我们换一个角度讨论这个问题。从泛左值和纯右值的作用来看:
- 泛左值表达式总是指代一个“实体”,可能是对象(变量)或函数等等;
- 纯右值表达式就是一个“裸”的表达式,它本身没有任何意义。只有当纯右值用作初始化器,或者作为运算符的操作数时,它才发挥作用。
这个定义是 C++17 “通过简化值类别以实现可靠的复制消除”提案(P0135)提出的,接近现行 C++ 标准中的描述。
由于泛左值表达式指代实体,而每个实体都具有身份(以表明它们是否是相同或不同实体)。而纯右值就像没有求值的数学公式一样,只有在被求值(也就是初始化别人/用作操作数)的那一刻才有用。对于它们来说是否是相同身份不重要,因此没有必要具有身份。
提示
[TODO] 例子
泛左值、纯右值这一对概念和之前提到的左值、右值概念非常接近。大部分泛左值就是左值,而纯右值表达式必然是右值。两者之间的差异在于亡值(xvalue):亡值是泛左值,但它是右值。
亡值
亡值是一个十分诡异的概念。先直接看下面的代码:
这里的两个表达式就是亡值了。亡值是泛左值的一部分,也就是说它们是有身份的。比如,表达式 1 所代表的实体是临时变量 Coord{4, 4} 的 x 成员,而表达式 2 则是同样的一个变量的 y 成员。由于它们有关联的实体,所以在定义上它们属于泛左值。假如我们可以对亡值赋值,则 Coord{4, 4}.x += 1 会让临时变量变成 {5, 4},而 Coord{4, 4}.y += 1 会让临时变量变成 {4, 5}。因此尽管这两个表达式的值相同,但某种意义上它们是可以区分的。
但亡值作为右值又不能出现在赋值运算符左侧,也不能取地址。也正因为亡值和纯右值都具有这样的性质,因此合称它们为右值。
此外,亡值是纯右值能够被使用的唯一途径。因为纯右值本身没有其所代表的实体对象,但亡值拥有。比如:
这个例子中,S{} 是纯右值:它就是一个表达式,两个 S{} 无法区分。此外,仅仅这个表达式不会让世界上诞生一个 S 类型对象,S{} 就静静地摆在那里,直到一个瞬间——“临时量实质化”(Temporary materialization)发生。临时量实质化的全称应该叫“右值到亡值转换”,比如第二个表达式 S{}.x 中试图使用纯右值 S{} 的成员,但纯右值仅仅作为表达式没有与之关联的对象,所以必须将这个关联的对象“实质化”出来。当这个实质化发生后,S{} 就成为了亡值;一旦成为了亡值,就可以从它所指代的实体(这里就是实质化出了 S 类型的临时对象)中访问成员 x 了。
临时量实质化发生在几乎所有可能使用纯右值的地方。比如表达式 a = 42 中的 42 虽然是纯右值,但它在实质化之前仅仅停留在 42 这两个字符的形式化意义上,只有实质化后,计算机才会构造出一个值为 42 的 int 类型变量,随后再用这个变量去做赋值。
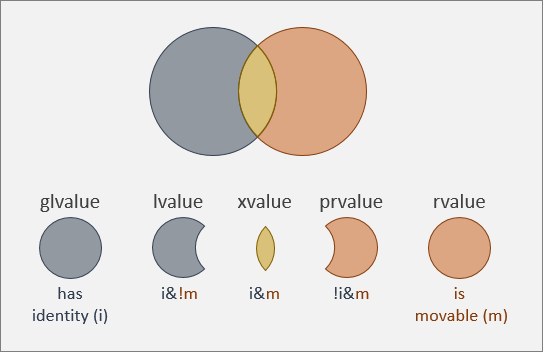
亡值和左值又有什么区别呢?本质上来说,它们没有区别。之后马上就会讲到,你甚至可以手动指定一个泛左值到底作为左值来使用还是亡值来使用。
复制消除 选读
临时量实质化的设计可以避免冗余的复制操作。
如果考虑字面意思的话,这段代码首先通过 S{} 构造一个 S 类型的临时对象,然后再从这个对象复制构造 a。但这里 S 的复制构造函数被删除了,a 却仍然可以从 S{} 初始化。原因就是, S{} 纯右值用来初始化变量时不发生临时量实质化,所谓的“S 类型临时对象”并不会存在。当临时量实质化被跳过后,S{} 就直接“原地”构造 a,即用 {} 初始化 a。
下面的例子也很常见:
当函数的 return 语句中是纯右值时,函数不进行临时量实质化而返回纯右值本身。也就是说,getS() 的值是 S{} 这个“裸”表达式,而非一个实打实存在的 S 类型对象。比较正常的返回过程:
这里 return 语句中已经是一个左值了,所以 getS() 返回的是一个已经存在的 S 类型对象 s。当返回发生时,s 复制初始化了 getS() 的值,也就是一次对象的复制。但上一个例子返回 S{} 这个“裸”表达式的时候复制的是“‘裸’表达式的形式”,形象地说就是把 S{} 从 return 语句“搬”到了调用处,并没有实际的复制发生。因此那个例子中复制构造函数可以被删除。
这本质上也是用纯右值初始化变量,只不过这里初始化的是
getS()的值。在初始化时临时量实质化被跳过,因此S{}直接“原地”替换了getS()。