指针的简单使用
这一节,我们从有关指针的三个运算符来讲解指针在使用方面的细节。
取地址运算
首先来看取地址运算。我们已经知道,对一个变量取地址,可以获得这个变量的地址:
int a;
&a; // 得到了 a 的地址
然而除了变量,其实还有一些东西可以是取地址运算符 & 的操作数。比如赋值表达式:
int a;
&(a = 42);
比如前缀自增表达式:
int a;
&++a;
那么这是什么道理呢?我们来介绍一个概念:表达式的值类别(Value category)。
表达式的值类别决定了这个表达式能否取到一个地址。其中,那些能够取到地址的表达式称为左值(lvalue),而那些无法取到地址的表达式称为右值(rvalue)。所以,只要一个表达式是左值,那么它就可以作为取地址运算符 & 的操作数。
那么都有哪些表达式是左值呢?很显然,变量属于左值(因为变量可以取到地址,前几节中一直是这样用的)。至于其它的表达式,那些运算结果可以确定到一个变量的表达式都是左值。比如:
- 简单赋值表达式:
a = 1。 - 复合赋值表达式:
a += 1。 - 前缀自增/减表达式:
++a--a。 - 解地址表达式:
*a。 - 下标表达式
a[i](大部分情形)。 - 逗号表达式
a, b,要求b是左值。 - 条件表达式
a ? b : c,要求b和c都是左值。 - ……
你会发现,这些表达式的结果都是一个变量,而不是一个孤零零的运算结果。什么叫“孤零零的”结果呢?比如:
- 非字符串的字面量:
42'A'3.14。这些字面量不能被取地址。 - 各种算术表达式、逻辑表达式、比较表达式
a + ba && ba > b。仅仅一个表达式的结果不会关联到任何一个变量。 - 后缀自增/减表达式
a++a--。因为它们的结果和运算完成后变量的值是不相等的;运算结果并不能指代那个变量。 - 取地址表达式
&a。取到的地址没有存放在任何一个变量里,所以它仅仅是一个运算结果。 - ……
像这种,表达式运算结果和变量毫无关系的,称为右值。
通过上面的讨论,我们知道了什么样的表达式能够取地址,什么样的不能:
int a;
&a; // OK
&(a = 1); // OK, a = 1 是左值
&(&a); // 错误,&a 是右值
&(a + 1); // 错误,a + 1 是右值
&42; // 错误,非字符串字面量是右值
int array[4]{};
&(array[0]); // OK, 下标表达式是左值
而且一般地,左值表达式大多能被赋值(数组除外),即出现在赋值运算符的左侧。
左值一词即源自“赋值运算符左侧”。但是目前更通用的解释为 Locationable value,即可寻址的值。同样地,右值的通用解释为 Readable value,即可读取的值。
解地址运算
一个地址可以通过解地址运算符 * 来获取这个地址存放的变量。解地址表达式 *p 的结果类型就是 p 的基类型。比如:
我们来简单地通过解地址运算来实现交换两个数。
这里第 10 行到第 12 行通过指针和指针的解地址交换了 a 和 b 两个变量的值。第 10 行先将 pa 指向的变量拷贝一份到 temp,然后将 pb 指向的内容赋值给 pa 指向的变量,最后再让 pb 指向的变量改为 temp。这个操作和之前交换变量的操作并无不同。
那么我们为什么非要用指针来实现交换两个数呢?明明直接对这两个变量操作就足够了,用指针操作有什么优点吗?答案是肯定的,请看这个例子:
我们可以把交换部分的代码用 exchange 函数给它包起来。这里,如果用变量作为形参,那么 exchange 函数并不会如期工作(因为实参初始化形参时发生了拷贝)。但是如果用指针作为形参,则一切就能正常运转:因为,exchange 函数得到的是地址——就是 main 函数里变量存放的位置。当你把这个位置交给 exchange 函数时,它便可以随意地通过这个地址去访问 main 中的变量。就好像你把你家门牌号告诉了其它人,那么这些人就可以随时随地通过门牌号找到你家。
还记得函数章节中 change 函数那个例子吗?同样地,现在我们可以通过将指针作为形参,成功实现在函数中修改 main 中局部变量的值:
这也就是指针的威力的体现——它可以无视任何障碍,不管是不是在一个函数内,直接读写指针指向变量的值。也正因为如此,进行指针操作时需要非常谨慎。
算术运算
我们现在来解释这个问题:明明指针存放的都是地址,为什么还需要指明基类型呢?通过下面这个例子,就能够体会到基类型的作用:
它的编译运行结果可能为:
0 0
0x4 0x2
你会发现, a 和 b 同样是指针,而且最初都是零值;但它们 +1 的结果却不同。这就是指针在执行加减运算时执行的策略:指针位移的长度取决于基类型的大小。
我们首先了解输出地址时得到的这个十六进制数的含义:它代表了这个地址到内存起始位置距离多少个字节。比如地址 0x62fe08 是指,它距离内存的开头有 个字节,即它是内存上的第 个字节(从 开始)。
对于指向 T 类型的指针,它 +1 的含义则是,让这个指针向后移动 sizeof(T) 个字节。比如刚才的例子中,sizeof(b) 为 2,所以 b + 1 使得原来为 0 的指针向后移动到 0x2;同理,sizeof(a) 若为 4,则 a + 1 向后移动到 0x4。(若 sizeof(long) 为 8,则移动到 0x8。)
类似地,若又一个指向 T 类型的指针 p,则 p + n 就是让这个指针向后移动 sizeof(T) * n 个字节。反之,p - n 就是让这个指针向前移动 sizeof(T) * n 个字节。
除此之外,两个指针之间可以做减法(如 p1 - p2),这样运算得到的结果是两个地址之间相差了多少个 sizeof(T)。
然而上面叙述的规则均是标准中未定义的;只有对指向数组元素的指针进行算术运算是被定义的行为。
指针的算术运算可以用下面的图片说明:
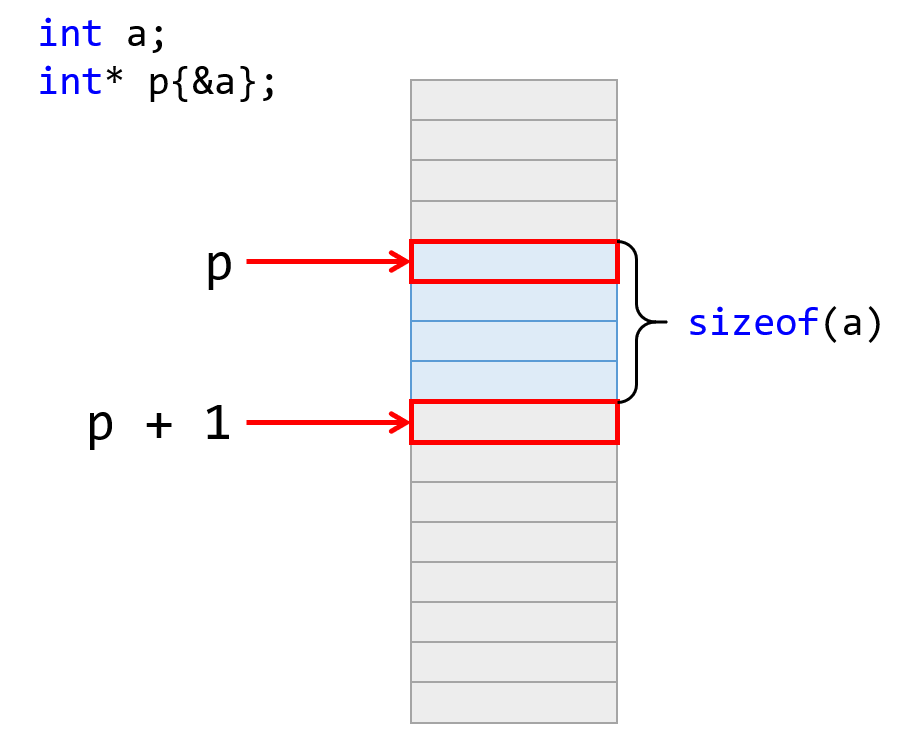
那么问题来了:为什么要这样设计指针的运算?它的主要用途其实是在数组上。指针和数组有着密不可分的联系,我将在下一节解释它。